
With AI being more implemented into applications there are new challenges for Quality Assurance (QA). While building traditional software has well-known testing practices, testing AI applications is something else. Unlike conventional code that follows predictable logic, AI systems are probabilistic, context-dependent, and can produce different outputs for the same input. A prompt that works perfectly in one setup may fail when context is added or a different Large Language Model (LLM) is used. At the same time not every LLM is the same. LLMs are created/trained differently, some are more lightweight, offering faster and cheaper responses at the expense of output quality. Others have more advanced reasoning capabilities to generate more complex outputs but will be more expensive and slower. I noticed this a lot during my experiments building agents, workflows and a project at a client where AI is used to generate metadata.
So how can we ensure that the AI applications/agents will be reliable, fast and cost efficient?
In this blog I would like to show some entry level examples on how you can use automated LLM evaluation with Promptfoo to measure and test the outcomes of prompt responses of various LLMs.
What is Promptfoo?
Promptfoo is an open-source LLM evaluation tool designed to automatically test and measure the quality of AI-generated outputs. Promptfoo offers A/B comparison of prompts and models, cost and latency tracking, and quality scoring using various evaluation methods including LLM-as-a-judge. To provide clear insights into test results, there’s also a simple but informative web view.
To install Promptfoo:

Setting up a Promptfoo test
Our goal is to set up a test which we can use to input multiple prompts and test the output of various models. Promptfoo tests are written in YAML and here’s a simple test setup:

Promptfoo offers various options to setup tests. First a description can be defined to describe a test scenario. A prompt is also needed to use as input to the LLM’s. The prompt includes two variables that we later can use to parse different numbers for different test cases. Next, we define the providers and their models for our tests. These are well-known models of Anthropic and OpenAI (don’t forget to setup your API keys for these providers).
Now that we have the first part of the setup we need to add assertions to validate the model outputs. I will divide these validations in two types:
- deterministic validation
- non-deterministic validation.
Deterministic validation
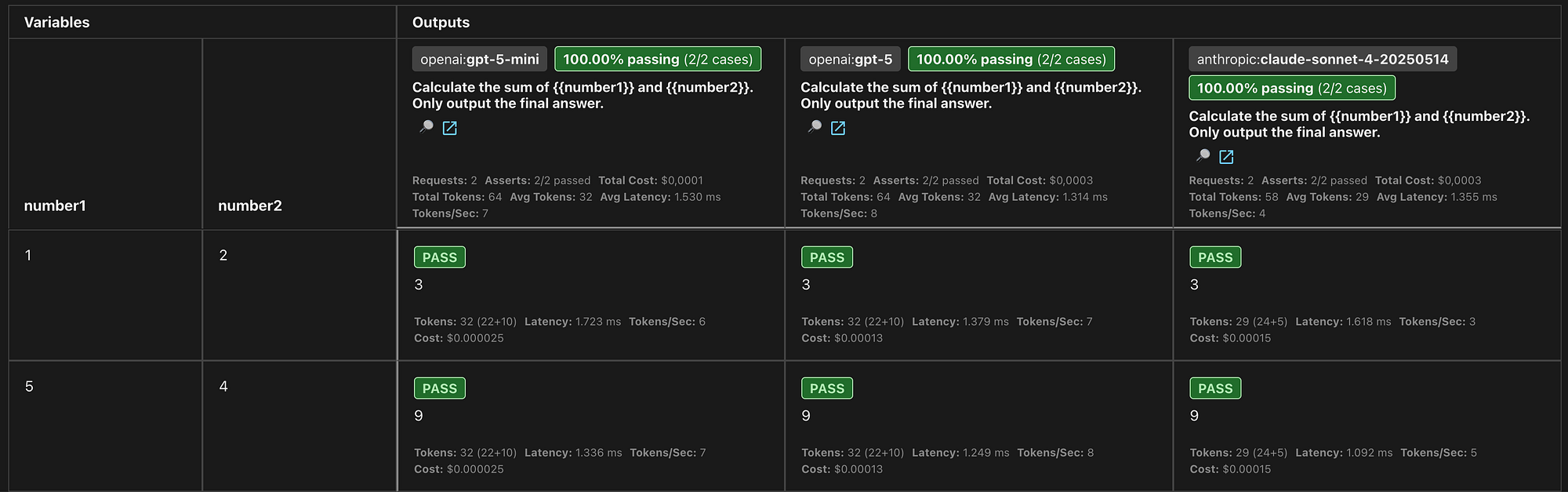
Deterministic validation uses exact matching rules to verify LLM outputs. With Promptfoo, you can check if responses contain specific keywords, match exact text patterns, or follow predefined formats. This approach is ideal for testing structured outputs such as JSON responses, specific answer formats, or scenarios requiring precise control over model outputs. In this example, we verify that the LLM correctly calculates the sum.

In this case we know what the output will be so a “equals” assertion is added that will do a exact string match. Now we are going to run the test:

To open the web view:

Non-deterministic validation
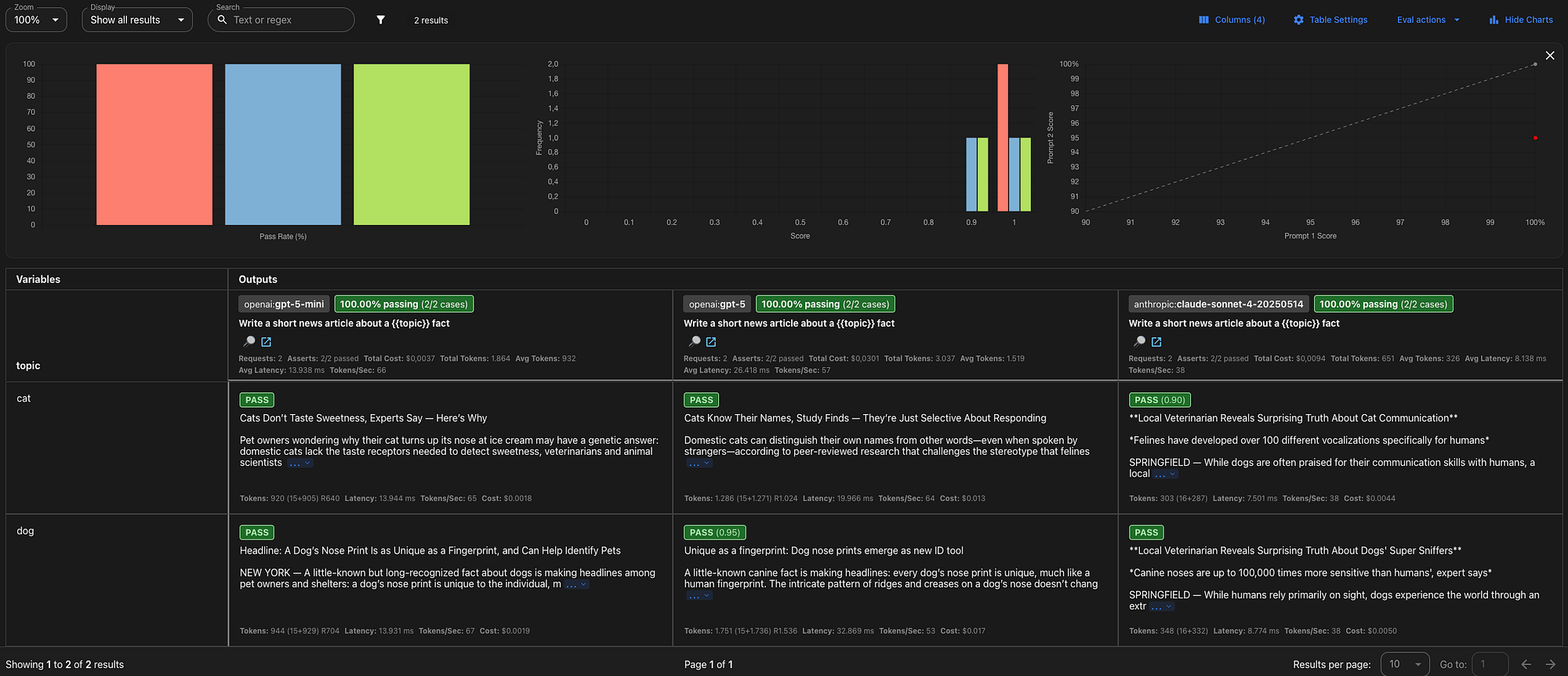
We cannot depend on deterministic checks if it is unknown what the exact output will be (non-deterministic). With Promptfoo’s LLM-as-a-Judge feature, you can have one model evaluate another model’s output. This method is suited for automated evaluation of non-deterministic outputs. In this example, we’ll prompt the LLM to write a news article about a topic, which we’ll define as a variable.

In the example above I have setup two testcases with each a “llm-rubric” assertion. This assertion is Promptfoo’s general purpose LLM-as-a-Judge assertion. Promptfoo offers multiple types of LLM-as-a-Judge assertions for specific purposes. The value contains instructions for the LLM-judge on what to evaluate. In the results the LLM-judge will also give a reason for it’s evaluation result.
In the example above I have setup two testcases with each a “llm-rubric” assertion. This assertion is Promptfoo’s general purpose LLM-as-a-Judge assertion. Promptfoo offers multiple types of LLM-as-a-Judge assertions for specific purposes. The value contains instructions for the LLM-judge on what to evaluate. In the results the LLM-judge will also give a reason for it’s evaluation result.
Web view of test results:
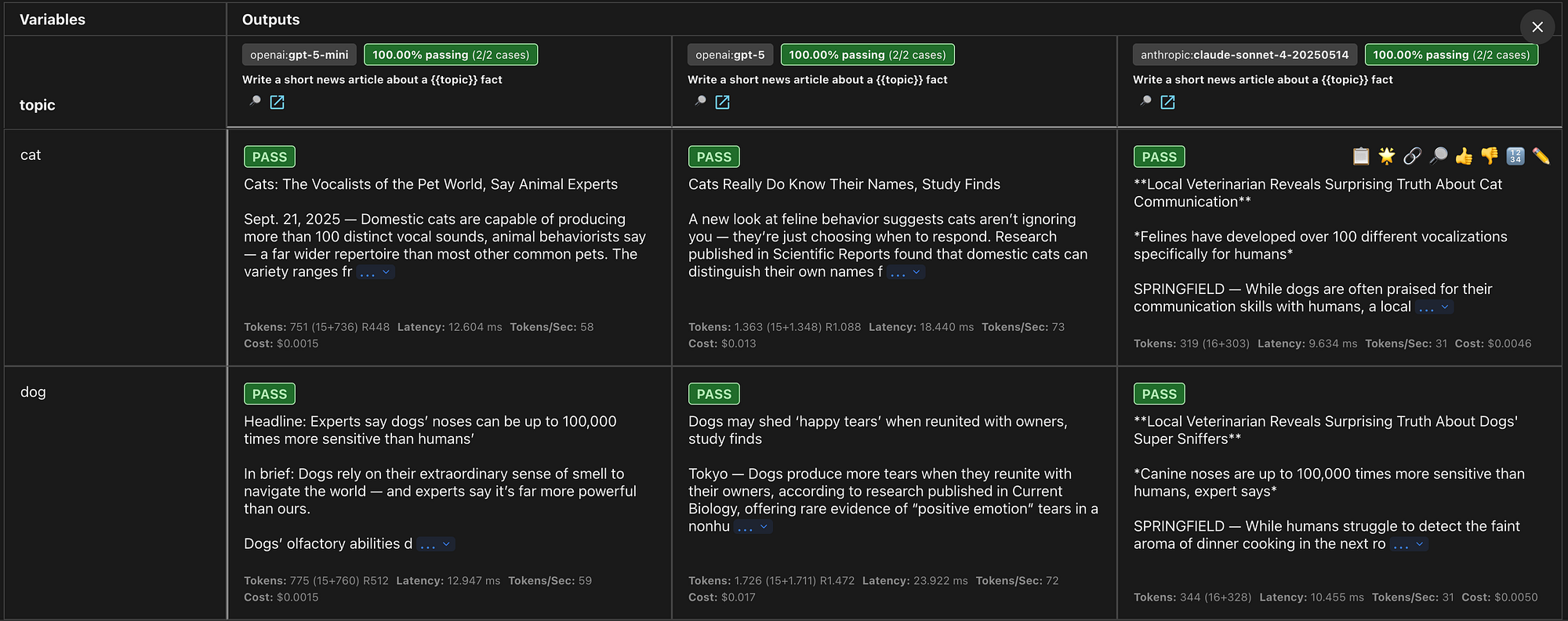
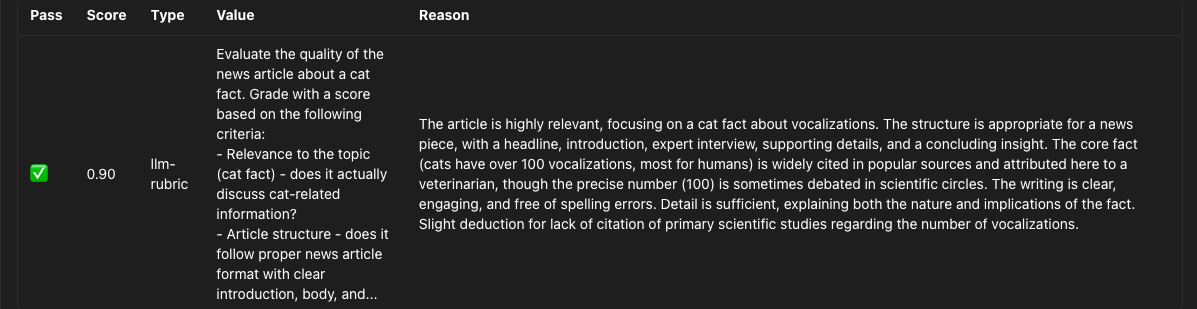
Evaluation result of llm-rubric assertion:

Grading outputs
When evaluating non-deterministic outputs, there’s typically no clear pass or fail result due to a large gray area where outputs may be partially correct. So when dealing with these outcomes it is best to have a measurement of the output quality. Instead of prompting the LLM-judge to judge if a output is true or false we will give it a prompt to grade the quality of the output and add a threshold on the score so it will fail the test when the score is too low.

Web view of test results:
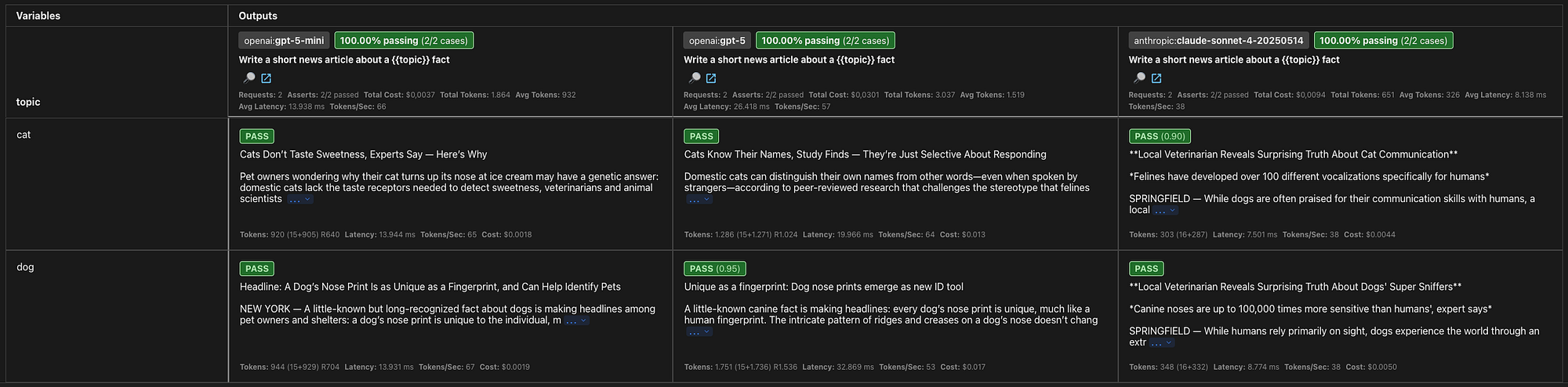
Evaluation result of llm-rubric assertion:
What’s next?
Based on the examples above the next things you can do with Promptfoo:
- Fine-tune prompts and LLM settings based on test results.
- Add latency and token cost assertions.
- Add custom providers to test agents or workflows. Promptfoo can execute Python or JavaScript files containing agents or workflows.
- Implement in CI/CD pipeline for automated regression testing.
- Automatic model selector for your AI application. If you have made the model that is used configurable you could potentially build a model selector in a CI/CD pipeline which will configure the best model based on the Promptfoo test results for the application deployment.
Conclusion
Measuring the quality of LLM outputs is challenging but is made far more insightful with Promptfoo. Remember to use different strategies for deterministic and non-deterministic outputs as I demonstrated in the examples. For non-deterministic validations like LLM-as-a-Judge keep in mind this does not 100% guarantee that the LLM outputs are valid. It does however provide developers and QA with a tool to set a baseline to measure quality and identify regression issues. I would say for now this is the best way to automatically test non-deterministic outputs, but be careful about what you will let the LLM-judge evaluate, since the judge itself is an LLM.
View the original article here. Do you have any questions about this topic? Feel free to contact us!


